In my current project we faced the challenge of deploying Cassandra cluster in Kubernetes. We don’t use any of the cloud providers for hosting Cassandra nor Kubernetes. Since the beginning, there were almost no problem with spinning a Cassandra cluster. Recently, however, because of our hardware setup, we faced the issue of making Cassandra rack aware on Kubernetes cluster.
Infrastructure
The setup is(n’t) straightforward. We have 6 VMs for Cassandra, which are grouped into 3 racks - 2 VMs per rack. All of the VMs for Cassandra are labeled in k8s, so that we guarantee with affinity rules, that only Cassandra instances will be deployed there. Additionally the VMs are labeled with rack information: rack-1, rack-2, rack-3. This is precisely the information I needed to push down through Kubernetes to Cassandra itself.
Kubernetes and DownwardAPI
After some quick investigation I found the Kubernetes DownwardAPI. Without too much of a view I was sure that I can use any label specified on node and put it into the container environment variable:
env:
- name: VM_LABEL
valueFrom:
fieldRef:
fieldPath: metadata.label[label/vm]Someone should have seen my face when I found out that you can only reference some restricted metadata with the DownwardAPI, and node labels isn’t one of them. There are even couple of issues and feature requests opened on how to pass through a node label into the pod:
- https://stackoverflow.com/questions/36690446/inject-node-labels-into-kubernetes-pod
- https://github.com/kubernetes/kubernetes/issues/62078
Tryout solution
So, ok, it’s not that easy but it’s not something that cannot be done right. In a moment I thought about using an initContainer to get the node label on which is the pod scheduled, and then add the label on to the pod. Shouldn’t be that hard, right:
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: node2pod
spec:
replicas: 1
template:
metadata:
labels:
name: node2pod
app: node2pod
spec:
initContainers:
- name: node2pod
image: k8s-cluster-image # that's tricky; for deployment via Gitlab Runner we created an image for controlling our k8s cluster from
# outside; exactly this image is used here
command:
- "sh"
- "-c"
- "kubectl -n ${NAMESPACE} label pods ${POD_NAME} vm/rack=$(kubectl get no -Lvm/rack | grep ${NODE_NAME} | awk '{print $6}')"
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
containers:
- name: nginx
image: nginx # for the purpose of the presenting the solution the image doesn't matter
env:
- name: RACK
valueFrom:
fieldRef:
fieldPath: metadata.labels['vm/rack']Well. Almost. Quite. But not what I’d expect. Though the pod was labeled:
kubernetes@node1:~# kubectl describe pod node2pod-557fb46b67-6qrgf
Namespace: default
Node: node7/<IP>
Start Time: Wed, 19 Sep 2018 10:20:33 +0200
Labels: app=node2pod
name=node2pod
pod-template-hash=1139602623
vm/rack=rack-2 the environment variable was empty inside the container. That’s due to the fact, that the resolution of env vars with DownwardAPI happens during pods scheduling and not execution. Dohhh. So another brainer. But fortunately with little help of a teammate of mine I finally made it with the following approach
Solution
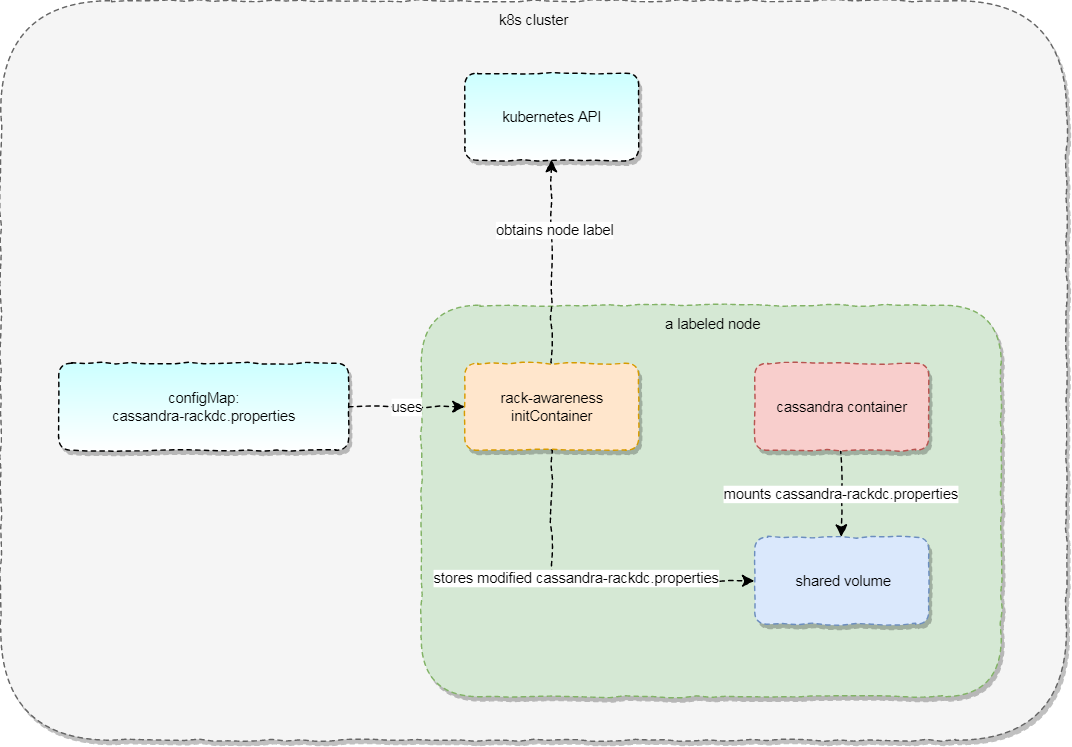
Just as a reminder, the original idea was to pass a node label to container with Cassandra inside, so it can use that information to configure Cassandra node with rack information. It’s also important to note that Cassandra is configured with multiple files, and one of them is cassandra-rackdc.properties which is the place where the rack information should finally be stored. The solution is not that simple, so a picture describes it best, but in steps:
configMapis used to store genericcassandra-rackdc.propertieswhich should be updated during deploymentinitContainertakes this (immutable)configMapand copies it onto a shared volume, which is shared with the Cassandra container- container mounts the shared volume and uses
subPathfor mounting just one of the files; we don’t want to overwrite other files
Drawing
The full blown yaml
For the purpose of readability, much configuration was removed
---
apiVersion: v1
kind: ConfigMap
metadata:
name: cassandra-rackdc
data:
cassandra-rackdc.properties: |
dc= datacenter
rack= RACK
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: cassandra
labels:
app: cassandra
spec:
podManagementPolicy: OrderedReady
replicas: 6
selector:
matchLabels:
app: cassandra
template:
metadata:
labels:
app: cassandra
name: cassandra
spec:
initContainers:
- name: cassandra-rack-awareness
image: k8s-cluster-image
command:
- "sh"
- "-c"
- "cp /cassandra/cassandra-rackdc.properties /shared/cassandra-rackdc.properties && \
sed -i.bak s/RACK/$(kubectl get no -Lvm/rack | grep ${NODE_NAME} | awk '{print $6}')/g /shared/cassandra-rackdc.properties"
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
volumeMounts:
- name: cassandra-rackdc
mountPath: /cassandra/
- name: shared
mountPath: /shared/
containers:
- name: cassandra
image: own-cassandra-image
env:
- name: CASSANDRA_SEEDS
value: "cassandra-0.cassandra.default.svc.cluster.local,cassandra-1.cassandra.default.svc.cluster.local,cassandra-2.cassandra.default.svc.cluster.local"
- name: CASSANDRA_ENDPOINT_SNITCH
value: "GossipingPropertyFileSnitch"
volumeMounts:
- name: shared
mountPath: /etc/cassandra/cassandra-rackdc.properties
subPath: cassandra-rackdc.properties
volumes:
- name: cassandra-rackdc
configMap:
name: cassandra-rackdc
- name: shared
emptyDir: {}Uff and yay!. The following is the proof that 4 of the nodes were up with proper rack settings:
root@cassandra-0:/# nodetool status
Datacenter: datacenter
==============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 10.33.128.4 108.63 KiB 256 51.4% 6f535d65-4076-469e-953b-f4676ed6b54a rack-1
UN 10.35.128.4 103.64 KiB 256 49.3% a7849387-2a55-448b-893c-b6d219a065f6 rack-2
UN 10.44.0.6 108.62 KiB 256 50.5% 2d1741cb-adff-4486-b1a8-b3b0fba410d2 rack-1
UN 10.43.64.4 69.94 KiB 256 48.9% 131d4fc5-60ec-4944-aa29-sfbbfb23a706 rack2Another job done!
Links
- Kubernetes
- Cassandra
- DownwardAPI
- https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-initialization/#create-a-pod-that-has-an-init-container
- https://github.com/kubernetes/kubernetes/issues/62078
- https://stackoverflow.com/questions/36690446/inject-node-labels-into-kubernetes-pod
- https://gist.github.com/gmaslowski/117f3535173d733e007d0c6c83564888